Explore LangChain AI Support for Knowledge Graph
Published on February 14, 2023 — 3 min read
Recently, LangChain AI, the Swiss-army knife for Large Language Model (LLM) based application development, has added support for graph data structures. As someone interested in the integration of LLMs and Knowledge Graph, I am thrilled to give it a try for the first time!
LangChain supports knowledge graph data represented as triple structures (subject, predicate and object), which is directly compatible with the RDF framework. Internally, the graph data is managed as directed graphs using the NetworkX package. Currently, LangChain provides two LLM-supported triple-related operations:
- Graph extraction: extract knowledge triples from a given piece of text
- Graph Q&A: utilize graph data as context for response synthesis
Thanks to the LangChain tracing capability, it is straightforward to understand the prompting strategies for the triple-related tasks, as illustrated in the following diagram. The exact prompt templates can be found on LangChain’s GitHub page (graph extraction and graph Q&A).
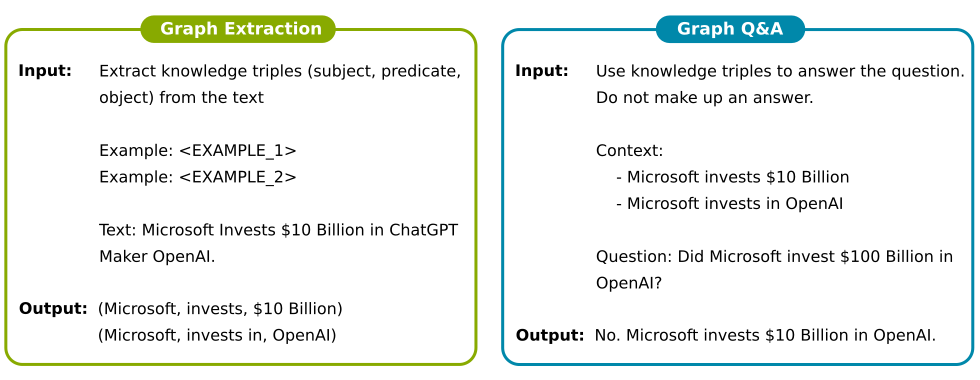
By default, LangChain uses LLMs, such as GPT-3, to extract triples from text and store them in a NetworkX directed graph
from langchain.indexes import GraphIndexCreator
from langchain.llms import OpenAI
index_creator = GraphIndexCreator(llm=OpenAI(temperature=0))
graph = index_creator.from_text('Microsoft Invests $10 Billion in ChatGPT Maker OpenAI.')
print(graph.get_triples())
# ('Microsoft', '$10 Billion', 'invests')
# ('Microsoft', 'ChatGPT Maker OpenAI', 'invests in')
However, it is also possible to add triples manually, although this approach is not publicly documented.
from langchain.graphs.networkx_graph import KnowledgeTriple
graph.add_triple(KnowledgeTriple('Google', '$300 Million', 'invests'))
graph.add_triple(KnowledgeTriple('Google', 'Anthropic', 'invests in'))
During graph-based Q&A, the graph serves as the context for response synthesis. Internally, the question is first fed into LLM to identify the key entities, which is then used to retrieve the relevant triples from the directed graph and generate the answer by LLM.
from langchain.chains import GraphQAChain
chain = GraphQAChain.from_llm(OpenAI(temperature=0), graph=graph, verbose=True)
chain.run("Does Microsoft invest $100 Billion to OpenAI?")
# "No, Microsoft invested $10 Billion to OpenAI."
Overall, this is a very exciting development towards the use of knowledge graphs for LLMs. It demonstrated the feasibility to extract, store and use triple-based knowledge in language chains, thus expanding LLM knowledge source beyond document stores.
This initial implementation also has several limitations for future improvement:
- Loading triples from existing knowledge graphs (either databases or files) is a must. The standardization of the RDF framework and the SPARQL query should make such a “graph loader” easy to build.
- When retrieving knowledge for a given entity, only triples in which the entity appears as the subject are retrieved, not as the object. This limits the kind of questions that can be answered (e.g. who invested in OpenAI?).
- The current triple retrieval mechanism may not scale well for large knowledge graphs or when indirect relationships are incorporated (depth > 1).
- Language ModelsGPTLangChain AIKnowledge Graph