ChatGPT for Information Retrieval from Knowledge Graph
Published on February 6, 2023 — 6 min read
Recently there has been a strong interest to augment GPT with external knowledge bases to improve the factuality of ChatGPT in domain-specific tasks. Large public knowledge graphs (KGs), such as WikiData, are ideal information sources for such purposes. However, effectively leveraging ChatGPT to interact with KGs remains an unsolved problem.
One approach is for ChatGPT to translate a given question into a SPARQL query, the standard KG query language, which is then used to retrieve relevant information from a KG. Similar to how a relational database is defined by a schema, a KG is defined by an ontology. Thus, we expect ChatGPT, when fed with both the question and the ontology, can potentially output the correct SPARQL query. However, one challenge, as raised by Dan Brickley, is that ontology is typically too large for GPT prompt.
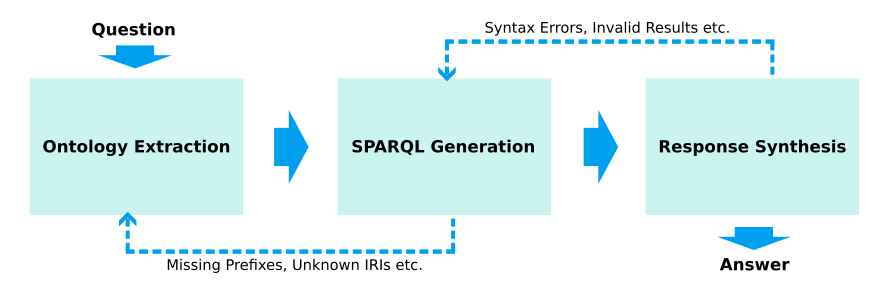
To address this challenge, I have been exploring the following workflow:
- Ontology Extraction: Use the question to create an ontology subset.
- SPARQL Generation: Formulate a SPARQL query based on the ontology subset.
- Response Synthesis: Query the KG and use the result to produce a response.
Additionally, error handling loops are followed when errors are encountered.
To test this hypothetical workflow, I have designed an experiment with the following parameters:
- Knowledge Graph: Open Citations Meta, a public repository of bibliographic metadata for scientific publications. (For improved query performance, a subset of the Meta dataset was loaded into a local BlazeGraph database.)
- Ontology: FaBio, the bibliographic ontology used by Open Citations Meta.
- Sample Question: “Can you retrieve the title, the journal, and the publication date for all journal articles that mention 'heart' in their title and were published in the 2000s?”
1. Ontology Extraction
The first step is creating an ontology subset small enough to fit in a GPT prompt. It includes several sub-steps as described below.

Using ChatGPT to recognize and extract keywords is straightforward, though separating entities and properties can be a little tricky.
To map keywords to ontology classes and properties, a naive approach was taken based on SPARQL queries with text filters. Inevitably, this picked up some classes that are not necessary for the query.
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT DISTINCT ?class {
?class a owl:Class ;
rdfs:label ?label .
FILTER(REGEX(?label, "article", "i"))
}
# output
# http://purl.org/spar/fabio/JournalIssue
# http://purl.org/spar/fabio/JournalVolume
# http://purl.org/spar/fabio/JournalNewsItem
# http://purl.org/spar/fabio/JournalEditorial
# http://purl.org/spar/fabio/Journal
# http://purl.org/spar/fabio/JournalArticle
Multiple approaches exist to prune an ontology depending on which relationships and logic entailments to preserve. To minimize the output size, I chose a simplistic approach of capturing only the matched classes (with their upper classes) and properties. The OBO ROBOT tool is handy for this task:
robot extract --method MIREOT --input fabio.ttl \
--lower-term "http://purl.org/spar/fabio/JournalIssue" \
--lower-term "http://purl.org/spar/fabio/JournalVolume" \
--lower-term "http://purl.org/spar/fabio/Journal" \
--lower-term "http://prismstandard.org/namespaces/basic/2.0/publicationDate" \
--lower-term "http://purl.org/dc/terms/title" \
...
--output fabio-slim.ttl
The resulting ontology subset is about ¼ size of the original ontology. It could be further minified by shortening prefixes, removing comments, and other techniques, but this was not pursued in this experiment.
2. SPARQL Generation
The ontology subset was then fed into ChatGPT along with the question to generate the SPARQL query.
The SPARQL produced by ChatGPT needs to be validated, as it often has missing prefixes or contains unknown IRIs as predicates. SPARQL parser and validator can help identify such issues. Once detected, errors can then be fed back to ChatGPT for refinement.
The simplistic ontology extraction showed its limitations here. Since no direct relationship is defined in the ontology subset between Journal and Journal Articles, ChatGPT “invented” a new predicate (“fabio:isPartOf”) to fill the gap. The root cause is that the specific relationship requires inference from their superclasses and/or using property paths. In order to proceed, I had to manually change "fabio:isPartOf" to "frbr:partOf*".
:JournalArticle a owl:Class ;
rdfs:label "journal article"@en ;
rdfs:comment "An article, typically the realization of a research paper reporting
original research findings, published in a journal issue. "@en ;
rdfs:subClassOf [ a owl:Restriction ;
owl:onProperty frbr:partOf ;
owl:someValuesFrom :JournalIssue ],
:Article .
# Similar axioms for
# :JournalIssue frbr:partOf :JournalVolume
# :JouranlVolume frbr:partOf :Journal
3. Response Synthesis
This last step is mostly uneventful, unless the SPARQL query led to error messages or obviously incorrect answers. Similar to step 2, we can try feeding the query back to the last step, along with the error messages, for refinement. Here is the final output from ChatGPT:
Reference List:
- Risk Factors For Heart Disease Associated With Abnormal Sidedness. Teratology, 2002-10-23.
- 13C-NMR Study Of Hypoglycemia-Induced Glycolytic Changes In Embryonic Mouse Heart. Teratology, 2002-10-23.
- The Heart Of Turner Syndrome: Small Matters. Teratology, 2002-07-22.
Summary
This experiment tested the feasibility of ontology-guided SPARQL query generation by ChatGPT for KG information retrieval. It revealed several limitations for future improvement: (1) the difficulty of mapping the question to a complete and compact ontology subset, especially when inference capability is needed, (2) the error-handling feedback loops are rather rudimentary. Additionally, feeding the ontology as chunks or translating ontology to a different representation are also interesting directions for future exploration.
- Language ModelChatGPTOntologyKnowledge GraphSPARQL