Augment GPT Response with External Knowledge using GPT Index
Published on January 27, 2023 — 3 min read
Large language models (LLMs) like GPT have remarkable language synthesis capabilities but struggle with maintaining factual correctness. Additionally, the “world knowledge” encoded in model parameters may not be sufficient to address domain-specific tasks. Therefore, prompting with additional context is often necessary, which however can be limited by the prompt size (for example, 2048 tokens for GPT-3). GPT Index is a Python library that employs various prompt engineering patterns and makes it easy to use a large body of external knowledge for GPT prompting.
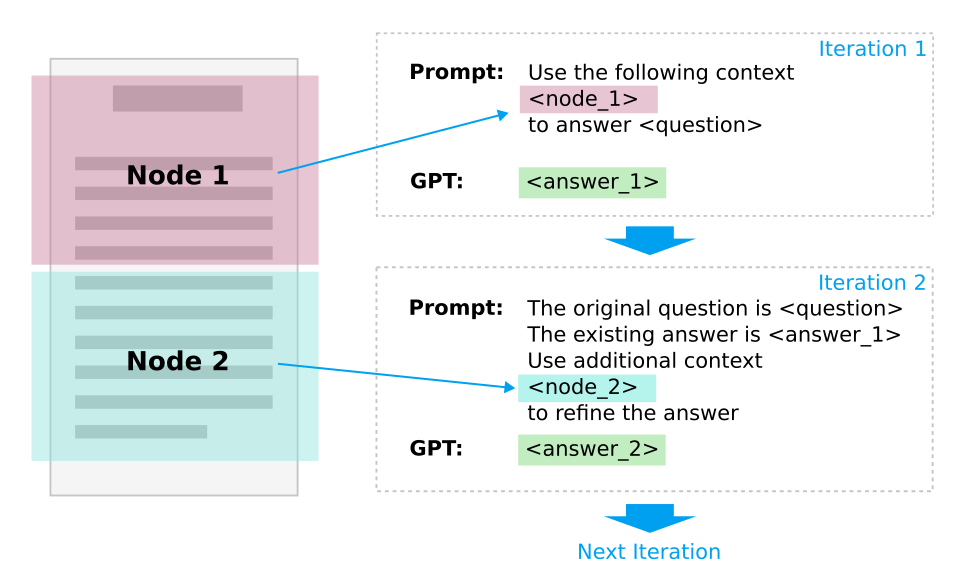
In the simplest terms, GPT Index divides a document into multiple chunks (nodes) and progressively feeds each node into GPT for answer refinement. The same strategy can also be applied to a set of documents or other bodies of text.
When the number of chunks (nodes) is high, it becomes impractical and inefficient to feed them all to GPT (The GPT Index cost estimator makes it particularly clear). GPT Index provides several index structures and routing mechanisms to minimize the number of input nodes:
- The naive approach is to feed all the nodes sequentially, with optional keyword-based filtering.
- The second approach is to use a decision tree to select a subset of candidate nodes.
- The third approach is to calculate embeddings for each node and pick the top n nodes based on vector similarity with the question.
In terms of response synthesis from the candidate nodes, GPT Index supports both iterative refinement through all the nodes (as illustrated in the diagram above), and recursive combination of multiple nodes in a bottoms-up fashion as in a tree structure.
While the package is called GPT Index, it is compatible with other LLMs as the “back end” and provides connectors with a range of data/document stores (Google Docs, SQL, MongoDB etc.).
In my preliminary exploration, GPT Index has proven to be quite effective in helping incorporate lengthy documents as context for Q&A and summarization tasks. Its APIs for such common usage patterns are easy to use. I highly recommend everyone give it a try, at least until LLMs can natively support integration with external knowledge bases. However, I do believe the current index design and search strategy may not yet scale well for very large knowledge bases, at least from a cost perspective. As a knowledge graph (KG) person, I think there are great opportunities to leverage semantic relationships and graph-based traversal capabilities in KG to facilitate information retrieval for LLMs. I am intrigued to see this area evolve in the near future.
- Language ModelsGPT