Explore OntoGPT for Schema-based Knowledge Extraction
Published on June 5, 2023 — 7 min read
Knowledge graphs (KGs) empower search engines, recommendation systems, data integration and enterprise knowledge management. More recently, it has also served as external memory for large language models (LLMs). However, automated knowledge extraction from unstructured text and its integration with pre-existing KGs present a notable challenge. Recent advancements in LLMs such as GPT offer encouring potential in addressing this issue.
A common technique is to directly translate each sentence into a triple format, essentially based on their syntactic structure. This method was implemented in popular LLM frameworks like LangChain and Llama Index. Nevertheless, such "autonomous extraction" has a few limitations: (1) the extracted knowledge triples may have consistency issues due to the lack of quality control; (2) the triples might not align with an predefined ontology, which limits their compatibility with existing KGs; (3) the technique may not be as effective when the desired triples are more abstractive or highly selective.
Recently, a more principled approach was developed by Chris Mungall and his team. Their OntoGPT GitHub Repo is laden with multiple specialized tools for KG engineering using LLMs, in which a key component is SPIRES (Structured Prompt Interrogation and Recursive Extraction of Semantics). In plain language, SPIRES is adept at extracting nested semantic structures, albeit at a shallow level, from text as guided by a schema. It then maps the extraction against existing knowledge bases, a process known as "grounding". For an additional layer of logical consistency or data accuracy, the extracted knowledge can be further examined using OWL reasoning or SHACL validation.
SPIRES employs an object-based extraction process. It initiates from a designed root object, extracting all its respective attributes. When an attribute is also identified as an object, the extraction repeats with this new target. This recursive process continues until the entire schema is exhausted. However, the authors advises against using more than 2 levels of nesting, as the extraction precision tends to decline beyond this.
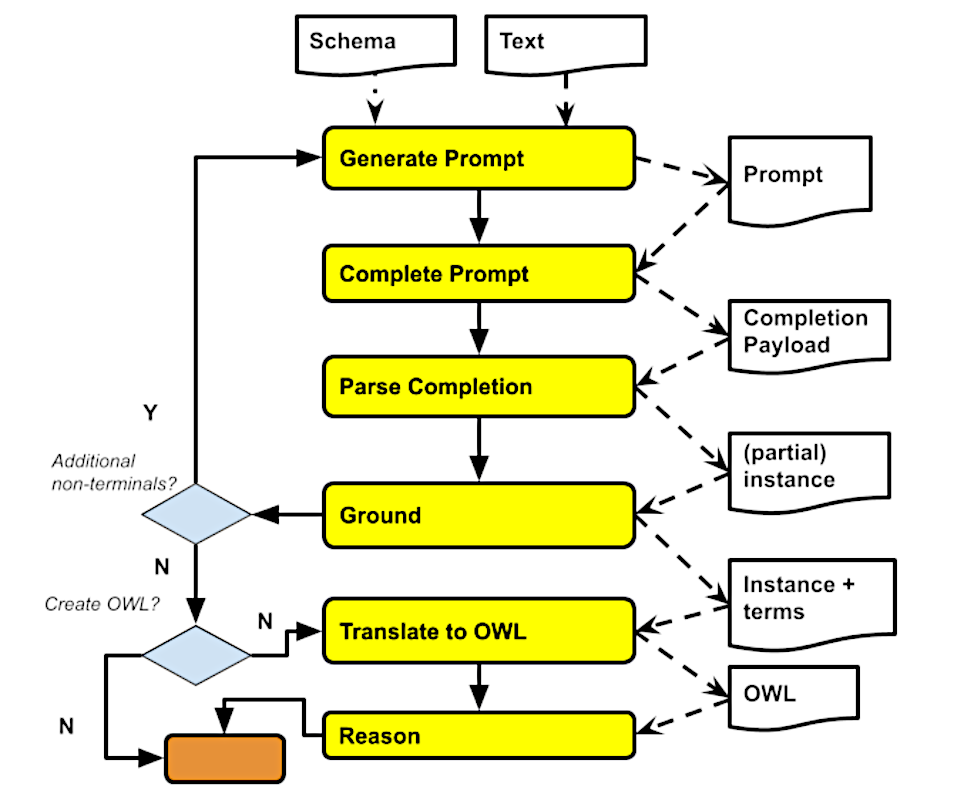
The schema system used by SPIRES is LinkML, a YAML-based language for describing ontologies, among other data schemas. The OntoGPT repo contains a number of pre-defined schema templates that cover a vast array of biomedical domains. Additionally, users can craft a new LinkML schema template, with SPIRES providing the necessary tooling to manage the extraction, grouding and validation processes. As a simple example, I have created a rudimentary schema to extract traffic advisory information from local news. Herein, TrafficAdvisory is the entry point for the extraction of its attributes, including other nested objects such as Location, State and County.
id: https://apex974.com/ids/traffic
name: traffic-advisory-template
title: Traffic Advisory Template
prefixes: <omitted>
imports:
- linkml:types
- core
classes:
TrafficAdvisory:
tree_root: true
attributes:
url:
identifier: true
range: uriorcurie
slot_uri: rdf:Resource
annotations:
prompt.ignore: true
label:
description: the name of the traffic advisory
slot_uri: rdfs:label
description:
description: a brief textual description of the traffic advisory
slot_uri: dcterms:description
categories:
description: the category of the traffic advisory. The permissible values are
construction, incident, event and others.
slot_uri: dcterms:subject
location:
description: the location of the traffic advisory
range: Location
Location:
attributes:
state:
description: States or territory of the United States
range: State
county:
description: Country within the state
range: County
State:
is_a: NamedEntity
id_prefixes:
- NCIT
attributes:
label:
description: the full name of the state
slot_uri: rdfs:label
annotations:
annotators: sqlite:obo:hp, sqlite:obo:ncit
County:
is_a: NamedEntity
attributes:
label:
description: the full name of the county
slot_uri: rdfs:label
SPIRES automatically compiles the YAML schemas into Pydantic models, which are subsequently used to construct prompts for GPT completion. Illustrated below is a prompt by SPIRES using the TrafficAdvisory template. The highlighted segment indicates the text input designated for extraction.
From the text below, extract the following entities in the following format:
url: <the value for url>
label: <the name of the traffic advisory>
description: <a brief textual description of the traffic advisory>
categories: <the category of the traffic advisory. The permissible values are construction,
incident, event and others.>
location: <the state which the traffic advisory is for>
Text:
CHARLOTTE COUNTY, Fla. (June 1, 2023) – Rio De Janeiro Avenue, between Sandhill and Deep
Creek boulevards, will be closed from 8 a.m. until 5 p.m. on Monday, June 5. This closure
is required for pipe repair. Detour signs will be in place to aid in travel through this
area. Travelers are encouraged to choose an alternate route when possible.?
The Public Works Department reminds motorists to?remain alert at all times?and to exercise
caution when traveling in the vicinity of construction zones.
For media, contact Tracy Doherty at 941-575-3643 or?Tracy.Doherty@CharlotteCountyFL.gov
The initial output is an unrefined assortment of key-value pairs, comprising the extracted attributes that may not be flawless. The next step involves parsing this raw output in accordance with the pydantic models, and if needed, repeating the extraction process for those attributes that are also objects. For classes that to be mapped to existing KGs, the extracted value is annotated against the KG to retrieve the instance ID (e.g. NCIT:C43478 for the state of Florida).
raw_completion_output: |-
url: N/A
label: Rio De Janeiro Avenue closure
description: Rio De Janeiro Avenue, between Sandhill and Deep Creek boulevards, will
be closed from 8 a.m. until 5 p.m. on Monday, June 5 for pipe repair. Detour signs
will be in place to aid in travel through this area. Travelers are encouraged to
choose an alternate route when possible.
categories: construction
location: Charlotte County, Florida
extracted_object:
url: N/A
label: Rio De Janeiro Avenue closure
description: Rio De Janeiro Avenue, between Sandhill and Deep Creek boulevards,
will be closed from 8 a.m. until 5 p.m. on Monday, June 5 for pipe repair. Detour
signs will be in place to aid in travel through this area. Travelers are encouraged
to choose an alternate route when possible.
categories: construction
location:
state: NCIT:C43478 # Florida
county: AUTO:Charlotte%20County
named_entities:
- id: NCIT:C43478
label: Florida
- id: AUTO:Charlotte%20County
label: Charlotte County
As with all LLM-based text processing, KG extraction is limited by the LLM context length. The recursive extraction strategy employed by SPIRES elivates this problem as one single object is targeted each time, but at the cost of increased LLM consumption. New LLM models, such as Claude-100K, supports much larger context length and hopefull will make it possible to use the entire ontology as input and/or to extract more complext knowledge as defined by nested or reified relationships.
To summarize, the OntoGPT framework and SPIRES tool offer a more structured method of extracting knowledge from unstructured text for integration into KGs. This object-oriented approach, while working within the constraints of LLMs, can handle complex, nested relationships and has a special focus on consistency, quality control and ontology alignment. I look forward to seeing how this framework can be further improved to support more complex knowledge extraction.
- Large Language ModelsGPTOntologyKnowledge Graph